昨晚,Anthropic(Claude)官网快闪了一篇经济指数的报告,看到很多自媒体也“无脑”发送了,包括里面明显的政治错误。看来,只要是公开发表的内容,还是有门槛的,不仅仅是技术层面,更在长期的专业训练层面。
昨晚我的工作重心都在如何生产视频上。但是除了明显的政治错误外,也还发现了一个奇怪的现象,就是这篇文章的日期写的是9月16日,也就是现在时间至少4小时以后。刚刚打开Anthropic官网,这篇文章居然消失了,我更相信这是一个提前发的“乌龙”,当然,幸好我提前把全文保存了下来,包括插图。
但是,实事求是讲,看起来用了很多数据,但都是很常识性的“发现”。
TL;DR,先说结论:
- 根据调查数据,虽然被调查企业AI使用率今年以来增长超过50%,但绝对比例依然只有10%,这个比例其实是很低的;
- 被宣传最多的发现是:越富有的国家和地区使用率越高,但这不是一个很常识性的发现吗?
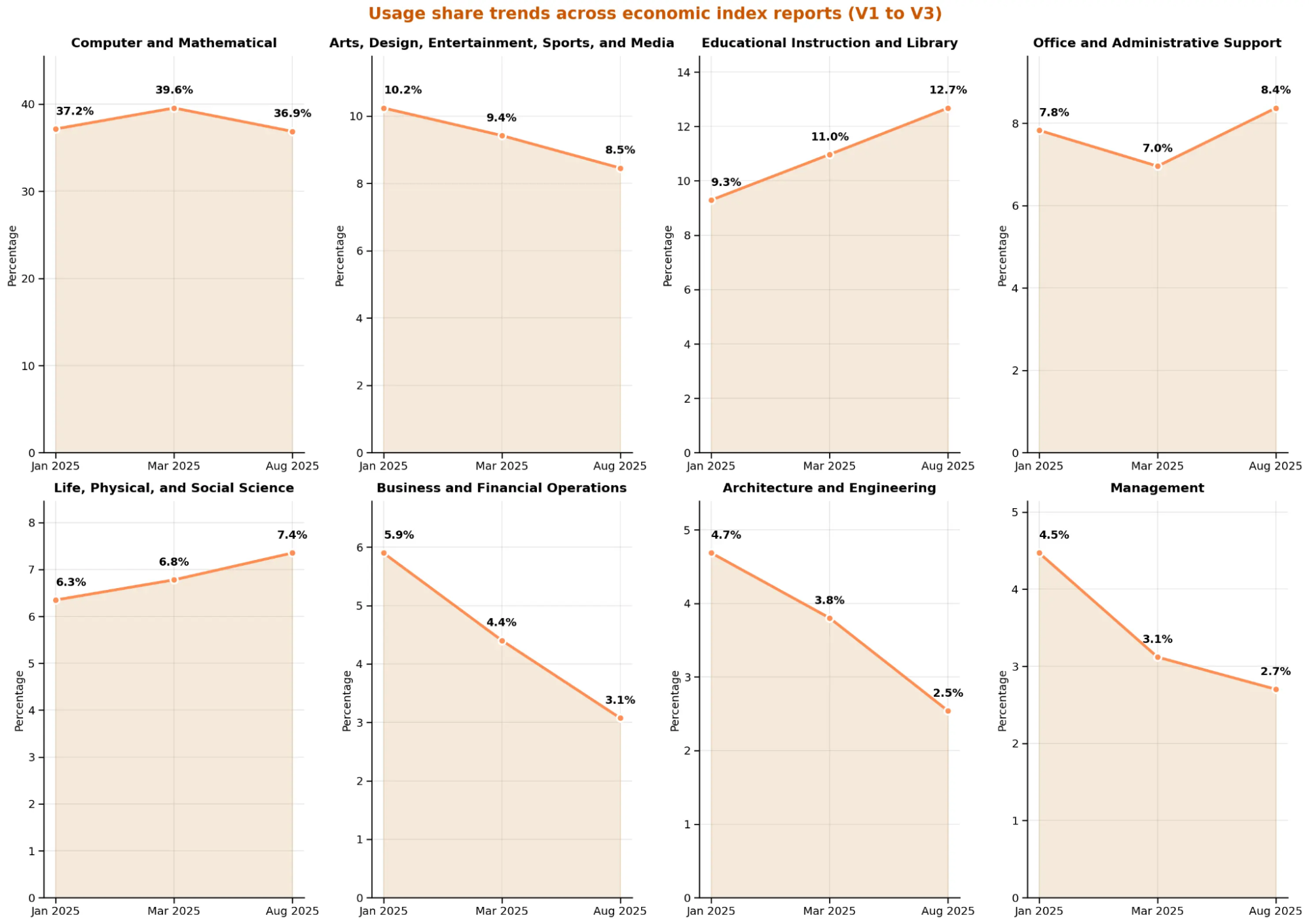
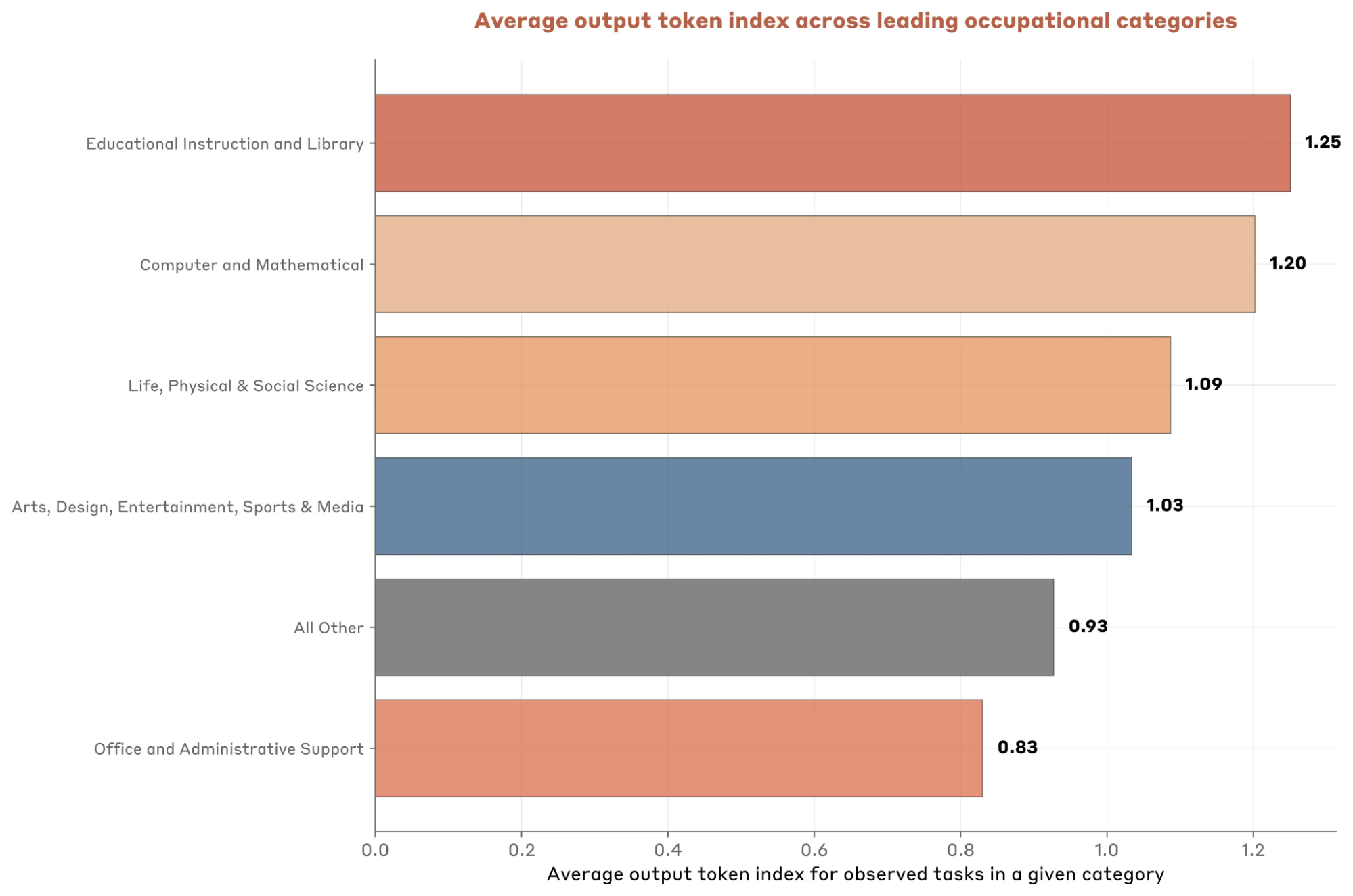
- 编程及数学任务(36.9%)依然是占比处于绝对统治地位的领域,但是教育(从9.3%到12.7%)占比上升很快,在商业金融、艺术与设计、管理、建筑与工程领域的占比则呈现持续下降的趋势。这是Claude模型的特点造成的(过度思考,过于理性但又“高幻觉”);
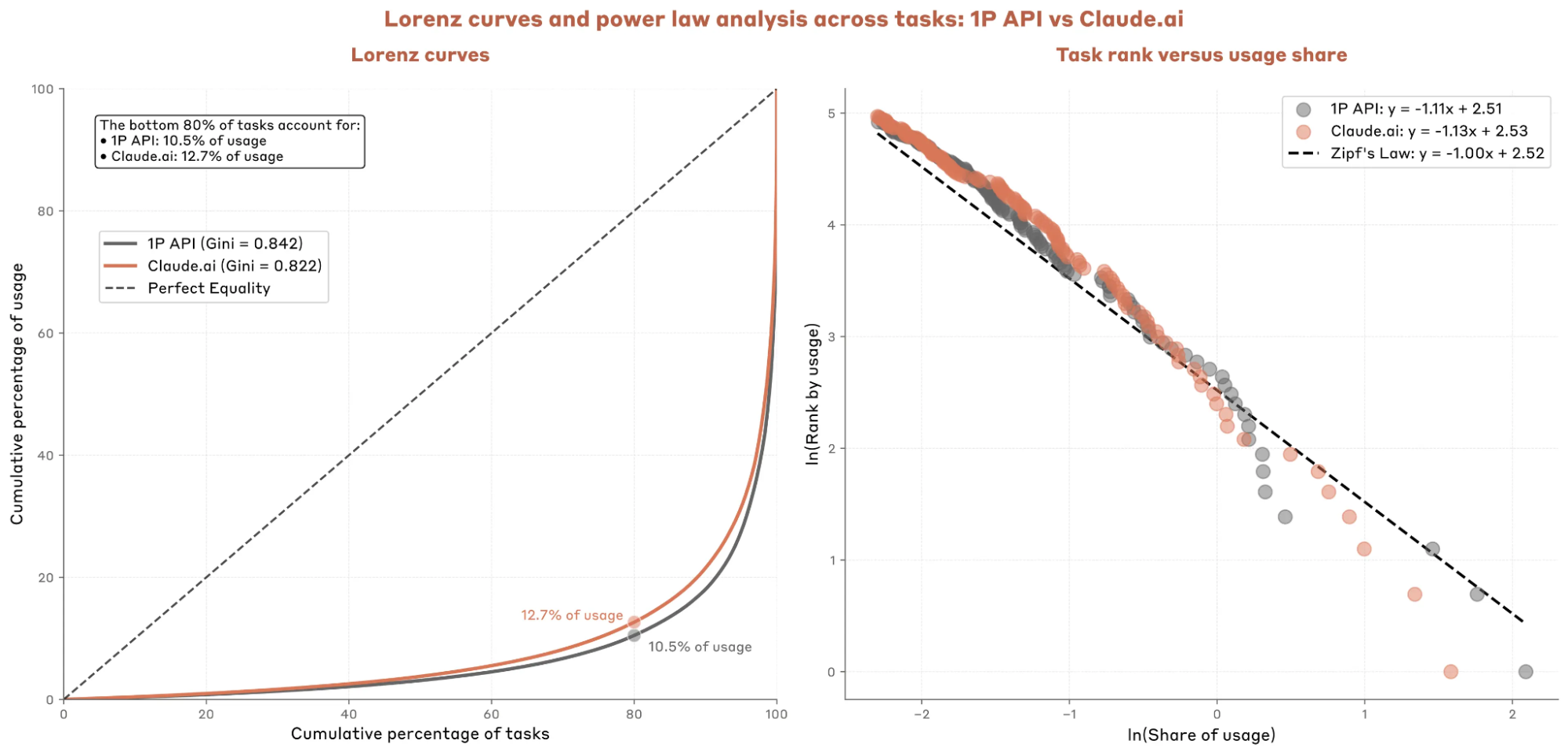
- 80%的任务只占了10.5%-12.7%的token使用量;
- AI使用无论从人群、应用领域看都是很不平衡的,虽然Claude因为模型特殊其实在数据上是“高估”这种不平衡的,但是这与常识还是非常符合的;但同时也看起来,我们离所谓的通用智能,其实还有很长的路要走;
好了,贴一些图及简单的解释。
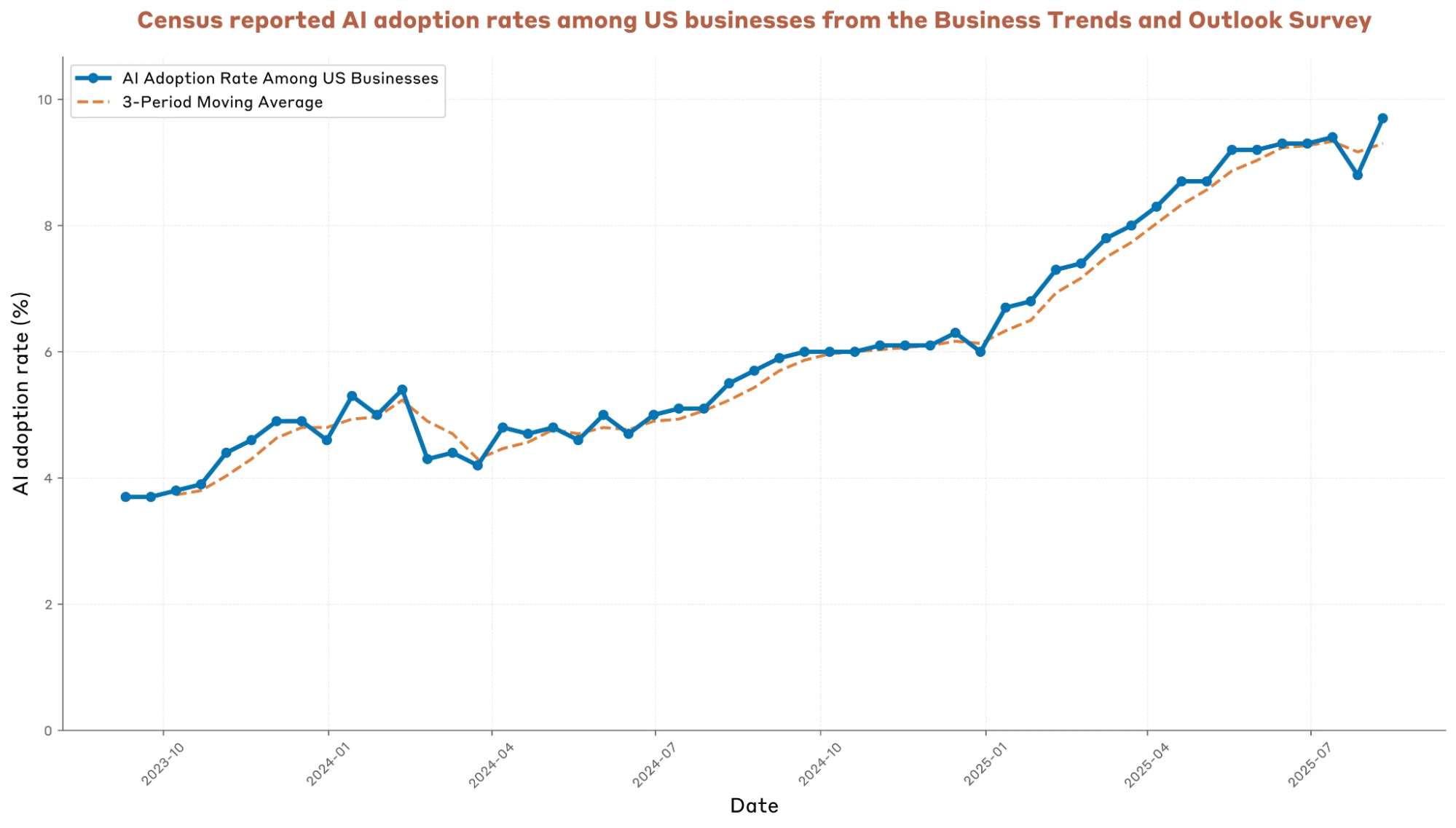
美国企业人工智能采用率,商业趋势与展望调查 (人口普查)。注:人工智能采用率计算为回答“是”的企业所占的比例,该问题为“在过去两周内,贵公司在生产商品或服务时是否使用了人工智能 (AI)?(人工智能示例:机器学习、自然语言处理、虚拟代理、语音识别等)”。
Claude.ai 使用随时间变化。每个面板显示了 Claude.ai 上与每个领域主要组任务相关的抽样对话的份额。我们看到科学和教育任务的使用量显著增加。领域按我们第一份报告中的使用量排名。
AI的使用率与该国家或者地区的人均GDP呈现显著的正相关关系(图不放了,有问题的就是这些图)。但是,我认为这个关系在Claude会被高估,原因很简单:Claude免费额度极少,Claude更多用来作为代码生成等以前门槛较高的任务中;
左边的洛伦兹曲线反映出,80%的任务只占了总使用量的10.5%-12.7%(API调用或者直接Claude应用);
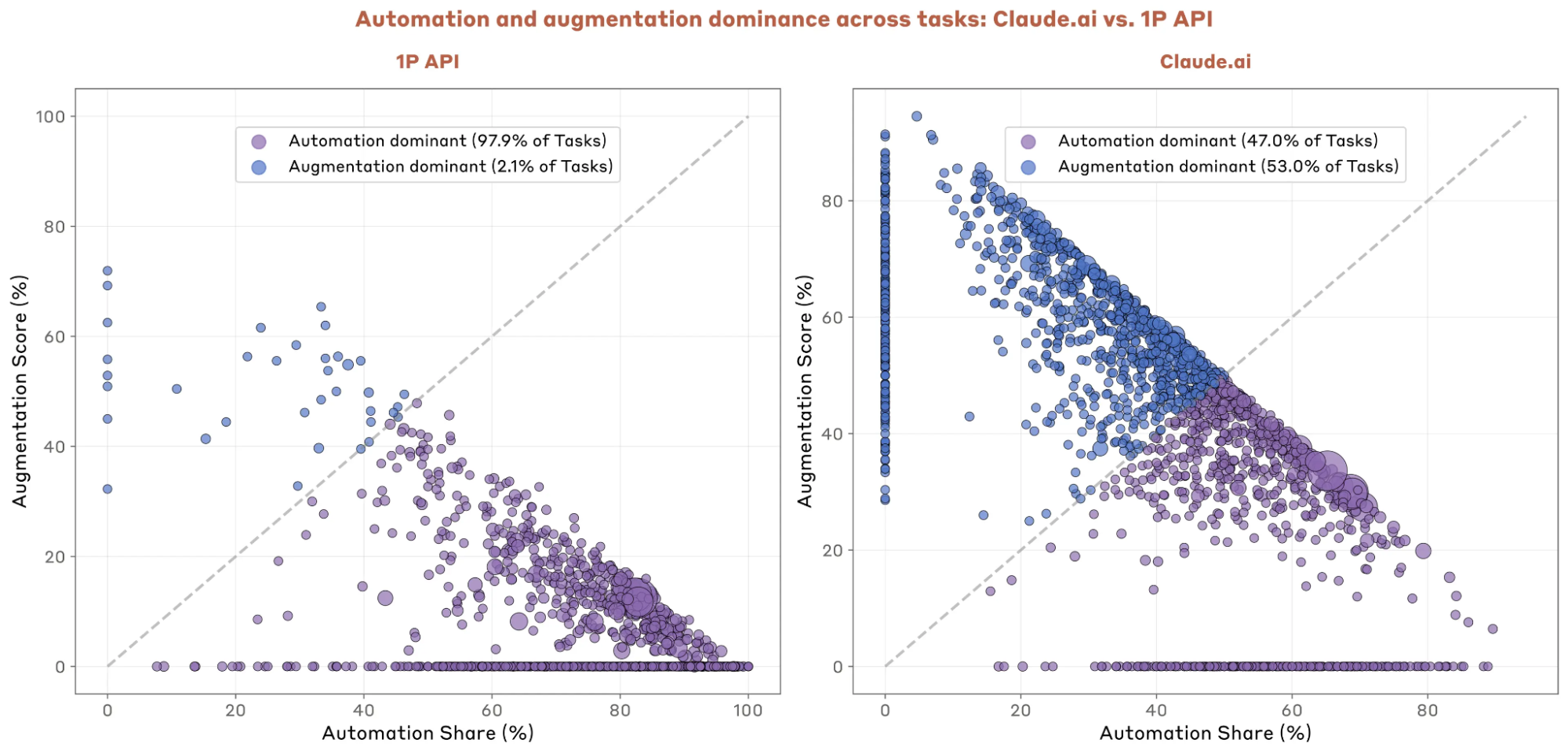
- 97%的API调用任务都是自动化的,相比之下,Claude应用中的比例只有47%;
- 在不同领域任务中,输出token的长度显示出显著的区别,按照Anthropic的统计,每1%的输入token的增长带来0.38%的输出token长度的增加,看起来,输入(上下文)与输出的比例差不多是3:1。但是这样的统计是有问题的,别忘了,20%的任务贡献了约90%的使用量。我们可以很容易的在气泡图的右上部分看出大量长上下文的任务输入token显著高于输出token一个数量级及以上。

- 在原文里,Anthropic提到,自从四月份推出“搜索”功能后,开启“互联网搜索”的任务占比从0.003%上升到0.27%,看起来增速很高,但是我相信绝对量相比ChatGPT和Gemini而言,一定是显著小的。这意味着,Claude的数据更可能高估了输出token的长度。